


/中文/
/中文/
/中文/
/中文/
/中文/
/中文/
/中文/
/中文/
/中文/
/中文/
删除重复图片的软件,由论坛大神原创制作的一个由Python编写的删除重复图片程序,可以一键删除文件中重复的图片资源,为您的PC节省空间,同时整理你的图库。需要能删除重复图片的软件的朋友们可以下载使用,单文件程序,绿色无广告。
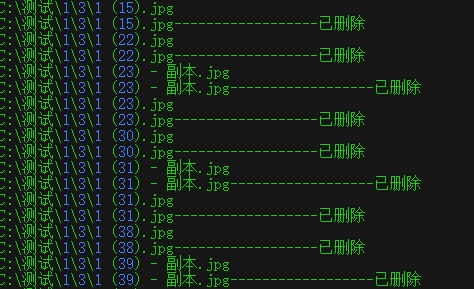
今天闲来无事整理素材,发现有许多重复的图片,由于数量太多无法手动翻阅删除,想想写个代码,分析了一下重复图片有些是同名的,有些内容重复不同名,返回文件名清理放弃,图片大小也放弃放弃,后来选用计算MD5的方式清除,然后先是使用os.listdir()函数遍历文件夹下的图片,在测试过程中,如果文件夹下还包含文件夹就会引发异常,后来决定用os.walk()函数来遍历;
源码注释写的比较清晰,就不多阐述,可根据自己需要封装函数,制作成死循环,添加退出条件,复用;
1、PictureEcho提供简单的扫描查询方式;
2、点击开始扫描就可以分析用户设置的地址;
3、提供多种重复选择功能,扫描到图片以后可以自己选择重复查询模式;
4、支持在重复的图片保存较小的图片,从而删除体积大的图片;
5、支持保留每个组中的最新图像,从而选中拍摄时间很久的老照片删除。
1、视觉相似度检测
4种相似度可供选择-显示准确,完整和清晰的结果;
2、精确重复的照片查找器
100%的相同照片被识别为重复照片;
3、自动选择重复的照片
根据文件大小,分辨率,文件历史记录和位置选择照片;
4、删除重复和相似的图像
永久删除重复的照片,占用磁盘空间;
5、图像预览和详细信息
预览结果,分析重复的照片和类似照片并采取措施;
6、将重复项移到新文件夹
创建一个新文件夹并在其中移动重复的图像。
import os,hashlib
import numpy as np
from PIL import Image,UnidentifiedImageError
from PIL.Image import DecompressionBombError
from rich import print
from time import time
print("""[#00CED1]待清理的文件夹内如果还包含了文件夹也同样可以清理![/#00CED1][#0000FF]
@@@@@@@@ @@@ @@@ @@@ @@@ @@@ @@@ @@@@@@ @@@ @@@ @@@ @@@@@@ @@@ @@@ @@@ @@@
@@@@@@@@ @@@ @@@ @@@ @@@ @@@ @@@ @@@@@@@@ @@@ @@@ @@@ @@@@@@@@ @@@ @@@ @@@@ @@@
@@! @@! @@@ @@! @@@ @@! @@@ @@! @@@ @@! @@! @@@ @@! @@@ @@! @@! @@!@!@@@
!@! !@! @!@ !@! @!@ !@! @!@ !@! @!@ !@! !@! @!@ !@! @!@ !@! !@! !@!!@!@!
@!!!:! @!@ !@! @!@!@!@! @!@ !@! @!@!@!@! @!! @!@ !@! @!@ !@! !!@ !!@ @!@ !!@!
!!!!!: !@! !!! !!!@!!!! !@! !!! !!!@!!!! !!! !@! !!! !@! !!! !!! !!! !@! !!!
!!: !!: !!! !!: !!! !!: !!! !!: !!! !!: !!: !!! !!: !!! !!: !!: !!: !!!
:!: :!: !:! :!: !:! :!: !:! :!: !:! :!: :!: !:! :!: !:! !!: :!: :!: :!: !:!
:: ::::: :: :: ::: ::::: :: :: ::: :: :::: ::::: :: ::::: :: ::: : :: :: :: ::
: : : : : : : : : : : : : : :: : : : : : : : : : ::: : :: :
[/#0000FF] [#00CED1]待清理的文件夹内还包含文件夹也可清理![/#00CED1]""")
path = input(r"输入图片文件夹路径,例如 D:\python\tupian:")
try:
file = os.walk(path) # 遍历目录;
except FileNotFoundError: # 捕获路径不存在异常;
print('抱歉,没有这个路径!')
else:
temp = set() # 创建临时集合;
del_count = 0 # 删除图片计数;
pass_count = 0 # 非图片计数;
file_count = 0 # 总文件计数;
time1 = time()
for path_name, dir_name, file_name in file: # 遍历walk返回3个元素;
for n in file_name: # 获得每个文件名字;
full_path = os.path.join(path_name, n) # 拼接路径和文件名,获得文件完整路径;
file_count += 1 # 文件计数+1;
print(full_path)
try:
with Image.open(full_path) as t: # 打开图片;
array = np.array(t) # 转为数组;
except (UnidentifiedImageError,DecompressionBombError): # 捕获不是图片,像素炸弹异常;
pass_count += 1 # 非图片计数+1;
pass
else:
md5 = hashlib.md5() # 创建MD5对象;
md5.update(array) # 获取当前图片MD5;
if md5.hexdigest() not in temp: # 如果哈希值没有在集合中;
temp.add(md5.hexdigest()) # 就把哈希值添加到集合中;
else:
os.remove(full_path) # 如果在集合中就删除当前图片;
print(full_path+'------------------已删除')
del_count += 1 # 删除计数+1;
time2 = time()
time3 = time2-time1
if pass_count != 0:
print('[#7CFC00]非图片数据:[/#7CFC00][#800000]{0}[/#800000] 个.'.format(pass_count))
print('[#800080]一共读取图片:[/#800080][#800000]{0}[/#800000] 张.'.format(file_count - pass_count))
print('[#3CB371]删除重复图片:[/#3CB371][#800000]{0}[/#800000] 张.'.format(del_count))
print('[#0000FF]总耗时为:[/#0000FF][#800000]{:.4f}[/#800000] 秒.'.format(time3))
input('按任意键结束!!!') # 此条为了编译成EXE或在命令行运行脚本时能看见上面统计后数据所添加,如果在IDE中运行可删除;
exit() # 如果在IDE中运行可删除;
 美图秀秀网页版(在线修图) 官方版图像处理
/ 729K
美图秀秀网页版(在线修图) 官方版图像处理
/ 729K
 南方cass9.1破解版64位/32位(免南方cass9.1加密狗) 绿色版图像处理
/ 66M
南方cass9.1破解版64位/32位(免南方cass9.1加密狗) 绿色版图像处理
/ 66M
 南方cass11.0免注册版64/32位版图像处理
/ 66M
南方cass11.0免注册版64/32位版图像处理
/ 66M
 南方cass10.0完美版64位 最新版图像处理
/ 34M
南方cass10.0完美版64位 最新版图像处理
/ 34M
 福昕pdf编辑器去水印绿色版(图像处理) v9.2 最新版图像处理
/ 109M
福昕pdf编辑器去水印绿色版(图像处理) v9.2 最新版图像处理
/ 109M
 procreate电脑中文版(专业级画图软件) v1.0 PC最新版图像处理
/ 24M
procreate电脑中文版(专业级画图软件) v1.0 PC最新版图像处理
/ 24M
 CorelDRAW X8中文版64位(附序列号) 免费版图像处理
/ 396M
CorelDRAW X8中文版64位(附序列号) 免费版图像处理
/ 396M
 网银转账截图软件(网银转账截图生成器) v1.5 最新版图像处理
/ 4.95M
网银转账截图软件(网银转账截图生成器) v1.5 最新版图像处理
/ 4.95M
 美图秀秀64位最新版v6.4.2.0 官方版图像处理
/ 15M
美图秀秀64位最新版v6.4.2.0 官方版图像处理
/ 15M
 常青藤4.2注册机(序列号生成) 免费版图像处理
/ 7K
美图秀秀网页版(在线修图) 官方版图像处理
/ 729K
南方cass9.1破解版64位/32位(免南方cass9.1加密狗) 绿色版图像处理
/ 66M
南方cass11.0免注册版64/32位版图像处理
/ 66M
南方cass10.0完美版64位 最新版图像处理
/ 34M
福昕pdf编辑器去水印绿色版(图像处理) v9.2 最新版图像处理
/ 109M
procreate电脑中文版(专业级画图软件) v1.0 PC最新版图像处理
/ 24M
CorelDRAW X8中文版64位(附序列号) 免费版图像处理
/ 396M
网银转账截图软件(网银转账截图生成器) v1.5 最新版图像处理
/ 4.95M
美图秀秀64位最新版v6.4.2.0 官方版图像处理
/ 15M
常青藤4.2注册机(序列号生成) 免费版图像处理
/ 7K
常青藤4.2注册机(序列号生成) 免费版图像处理
/ 7K
美图秀秀网页版(在线修图) 官方版图像处理
/ 729K
南方cass9.1破解版64位/32位(免南方cass9.1加密狗) 绿色版图像处理
/ 66M
南方cass11.0免注册版64/32位版图像处理
/ 66M
南方cass10.0完美版64位 最新版图像处理
/ 34M
福昕pdf编辑器去水印绿色版(图像处理) v9.2 最新版图像处理
/ 109M
procreate电脑中文版(专业级画图软件) v1.0 PC最新版图像处理
/ 24M
CorelDRAW X8中文版64位(附序列号) 免费版图像处理
/ 396M
网银转账截图软件(网银转账截图生成器) v1.5 最新版图像处理
/ 4.95M
美图秀秀64位最新版v6.4.2.0 官方版图像处理
/ 15M
常青藤4.2注册机(序列号生成) 免费版图像处理
/ 7K





