


/中文/
/中文/
/中文/
/中文/
/中文/
/中文/
/中文/
/中文/
/中文/
/中文/
kafka能够针对分布式发布消息进行动作流量数据统计,许多的方法和参数都在kafka权威指南pdf中文版中提供给你!精心制作的kafka电子书教程下载免费即可下载去通过语言简单精炼清晰来让kafka权威指南pdf中文版教会你更多kafka相关的技巧和知识,让你使用kafka更加简单轻松!
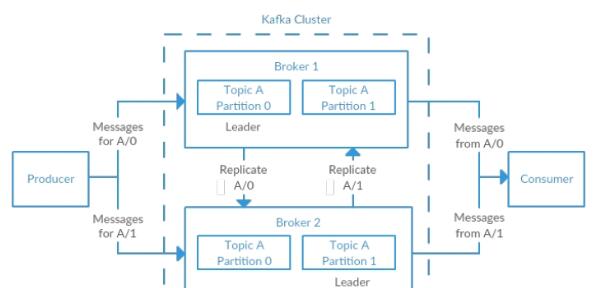
Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者规模的网站中的所有动作流数据。 这种动作(网页浏览,搜索和其他用户的行动)是在现代网络上的许多社会功能的一个关键因素。 这些数据通常是由于吞吐量的要求而通过处理日志和日志聚合来解决。 对于像Hadoop的一样的日志数据和离线分析系统,但又要求实时处理的限制,这是一个可行的解决方案。Kafka的目的是通过Hadoop的并行加载机制来统一线上和离线的消息处理,也是为了通过集群来提供实时的消费。
Partition
Partition是物理上的概念,每个Topic包含一个或多个Partition.
Producer
负责发布消息到Kafka broker
Consumer Group
每个Consumer属于一个特定的Consumer Group(可为每个Consumer指定group name,若不指定group name则属于默认的group)。
Consumer
消息消费者,向Kafka broker读取消息的客户端。
Broker
Kafka集群包含一个或多个服务器,这种服务器被称为broker
Topic
每条发布到Kafka集群的消息都有一个类别,这个类别被称为Topic。(物理上不同Topic的消息分开存储,逻辑上一个Topic的消息虽然保存于一个或多个broker上但用户只需指定消息的Topic即可生产或消费数据而不必关心数据存于何处)
 uninstall tool密钥最新版网络辅助
/ 1K
uninstall tool密钥最新版网络辅助
/ 1K
 diskgenius离线激活码永久版网络辅助
/ 37M
diskgenius离线激活码永久版网络辅助
/ 37M
 守望先锋dva本子完整版(内含视频) 高清网盘版网络辅助
/ 1M
守望先锋dva本子完整版(内含视频) 高清网盘版网络辅助
/ 1M
 友邦微信群发软件(微信推广工具) v5.7 最新版网络辅助
/ 27.84M
友邦微信群发软件(微信推广工具) v5.7 最新版网络辅助
/ 27.84M
 吉吉影音资源BT种子(吉吉影音看片网站) 免费版网络辅助
/ 397K
吉吉影音资源BT种子(吉吉影音看片网站) 免费版网络辅助
/ 397K
 网页自动点击操作助手电脑版(自动刷网页点击数) v19.1.0 免费版网络辅助
/ 8M
网页自动点击操作助手电脑版(自动刷网页点击数) v19.1.0 免费版网络辅助
/ 8M
 CDR注册机(cdr永久激活代码) 免费版网络辅助
/ 323K
CDR注册机(cdr永久激活代码) 免费版网络辅助
/ 323K
 一片云验证码平台(验证码接收工具) v6.4 官方最新版网络辅助
/ 1004K
一片云验证码平台(验证码接收工具) v6.4 官方最新版网络辅助
/ 1004K
 360种子在线编辑器(360种子洗白工具) v1.0.1 绿色免费版网络辅助
/ 1M
360种子在线编辑器(360种子洗白工具) v1.0.1 绿色免费版网络辅助
/ 1M
 奥维互动地图vip账号分享工具(奥维地图vip账号大全) v2017 免费版网络辅助
/ 28M
吉吉影音资源BT种子(吉吉影音看片网站) 免费版网络辅助
/ 397K
uninstall tool密钥最新版网络辅助
/ 1K
diskgenius离线激活码永久版网络辅助
/ 37M
守望先锋dva本子完整版(内含视频) 高清网盘版网络辅助
/ 1M
友邦微信群发软件(微信推广工具) v5.7 最新版网络辅助
/ 27.84M
网页自动点击操作助手电脑版(自动刷网页点击数) v19.1.0 免费版网络辅助
/ 8M
CDR注册机(cdr永久激活代码) 免费版网络辅助
/ 323K
360种子在线编辑器(360种子洗白工具) v1.0.1 绿色免费版网络辅助
/ 1M
一片云验证码平台(验证码接收工具) v6.4 官方最新版网络辅助
/ 1004K
奥维互动地图vip账号分享工具(奥维地图vip账号大全) v2017 免费版网络辅助
/ 28M
奥维互动地图vip账号分享工具(奥维地图vip账号大全) v2017 免费版网络辅助
/ 28M
吉吉影音资源BT种子(吉吉影音看片网站) 免费版网络辅助
/ 397K
uninstall tool密钥最新版网络辅助
/ 1K
diskgenius离线激活码永久版网络辅助
/ 37M
守望先锋dva本子完整版(内含视频) 高清网盘版网络辅助
/ 1M
友邦微信群发软件(微信推广工具) v5.7 最新版网络辅助
/ 27.84M
网页自动点击操作助手电脑版(自动刷网页点击数) v19.1.0 免费版网络辅助
/ 8M
CDR注册机(cdr永久激活代码) 免费版网络辅助
/ 323K
360种子在线编辑器(360种子洗白工具) v1.0.1 绿色免费版网络辅助
/ 1M
一片云验证码平台(验证码接收工具) v6.4 官方最新版网络辅助
/ 1004K
奥维互动地图vip账号分享工具(奥维地图vip账号大全) v2017 免费版网络辅助
/ 28M





