


/中文/
/中文/
/中文/
/中文/
/中文/
/中文/
/中文/
/中文/
/中文/
/中文/
PowerJob是新一代分布式任务调度与计算框架,支持CRON、API、固定频率、固定延迟等调度策略,提供工作流来编排任务解决依赖关系,使用简单,功能强大,文档齐全。

PowerJob是一款任务调度框架设计源码,可帮助变成人员快速设计出任务调度的框架,按照自己的设定自由更改后,就能完美开发出需要的任务调度软件。对于变成人员来说使用起来非常简单,直接上手就能用,而且定制完后任务调度功能,完全能够满足日常工作使用的需求。
有定时执行需求的业务场景:如每天凌晨全量同步数据、生成业务报表等。
有需要全部机器一同执行的业务场景:如使用广播执行模式清理集群日志。
有需要分布式处理的业务场景:比如需要更新一大批数据,单机执行耗时非常长,可以使用Map/MapReduce处理器完成任务的分发,调动整个集群加速计算。
有需要延迟执行某些任务的业务场景:比如订单过期处理等。
使用简单:提供前端Web界面,允许开发者可视化地完成调度任务的管理(增、删、改、查)、任务运行状态监控和运行日志查看等功能。
定时策略完善:支持CRON表达式、固定频率、固定延迟和API四种定时调度策略。
执行模式丰富:支持单机、广播、Map、MapReduce四种执行模式,其中Map/MapReduce处理器能使开发者寥寥数行代码便获得集群分布式计算的能力。
DAG工作流支持:支持在线配置任务依赖关系,可视化得对任务进行编排,同时还支持上下游任务间的数据传递
执行器支持广泛:支持Spring Bean、内置/外置Java类、Shell、Python等处理器,应用范围广。
运维便捷:支持在线日志功能,执行器产生的日志可以在前端控制台页面实时显示,降低debug成本,极大地提高开发效率。
依赖精简:最小仅依赖关系型数据库(MySQL/Oracle/MS SQLServer...),扩展依赖为MongoDB(用于存储庞大的在线日志)。
高可用&高性能:调度服务器经过精心设计,一改其他调度框架基于数据库锁的策略,实现了无锁化调度。部署多个调度服务器可以同时实现高可用和性能的提升(支持无限的水平扩展)。
故障转移与恢复:任务执行失败后,可根据配置的重试策略完成重试,只要执行器集群有足够的计算节点,任务就能顺利完成。
STEP1: 初始化项目
导入 IDE,源码结构如下,我们需要启动调度服务器(powerjob-server),同时在samples工程中编写自己的处理器代码

STEP2: 启动调度服务器
创建数据库(仅需要创建数据库):找到你的DB,运行SQLCREATE DATABASE IF NOT EXISTS `powerjob-daily` DEFAULT CHARSET utf8mb4,搞定~
修改配置文件,配置文件的说明官方文档写的非常详细,此处不再赘述。需要修改的地方为数据库配置spring.datasource.core.jdbc-url、spring.datasource.core.username和spring.datasource.core.password,当然,有mongoDB的同学也可以修改spring.data.mongodb.uri以获取完全版体验。
oms.env=DAILY
logging.config=classpath:logback-dev.xml
####### 外部数据库配置(需要用户更改为自己的数据库配置) #######
spring.datasource.core.driver-class-name=com.mysql.cj.jdbc.Driver
spring.datasource.core.jdbc-url=jdbc:mysql://localhost:3306/powerjob-daily?useUnicode=true&characterEncoding=UTF-8&serverTimezone=Asia/Shanghai
spring.datasource.core.username=root
spring.datasource.core.password=No1Bug2Please3!
spring.datasource.core.hikari.maximum-pool-size=20
spring.datasource.core.hikari.minimum-idle=5
####### mongoDB配置,非核心依赖,通过配置 oms.mongodb.enable=false 来关闭 #######
oms.mongodb.enable=true
spring.data.mongodb.uri=mongodb://localhost:27017/powerjob-daily
####### 邮件配置(不需要邮件报警可以删除以下配置来避免报错) #######
spring.mail.host=smtp.163.com
spring.mail.username=zqq@163.com
spring.mail.password=GOFZPNARMVKCGONV
spring.mail.properties.mail.smtp.auth=true
spring.mail.properties.mail.smtp.starttls.enable=true
spring.mail.properties.mail.smtp.starttls.required=true
####### 资源清理配置 #######
oms.instanceinfo.retention=1
oms.container.retention.local=1
oms.container.retention.remote=-1
####### 缓存配置 #######
oms.instance.metadata.cache.size=1024
完成配置文件的修改后,可以直接通过启动类com.github.kfcfans.powerjob.server.OhMyApplication启动调度服务器,观察启动日志,查看是否启动成功~启动成功后,访问 http://127.0.0.1:7700/ ,如果能顺利出现Web界面,则说明调度服务器启动成功!
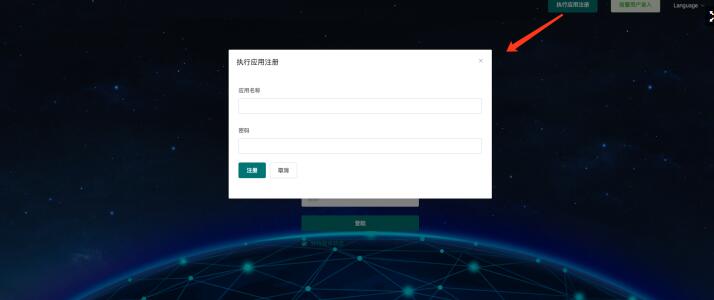
注册应用:点击主页应用注册按钮,填入powerjob-agent-test和控制台密码(用于进入控制台),注册示例应用(当然你也可以注册其他的appName,只是别忘记在示例程序中同步修改~)
STEP3: 编写示例代码
进入示例工程(powerjob-worker-samples),修改配置文件连接powerjob-server并编写自己的处理器代码。
修改 powerjob-worker-samples 的 application.properties,将 powerjob.app-name 改为刚刚在控制台注册的名称。
server.port=8081
spring.jpa.open-in-view=false
########### powerjob-worker 配置 ###########
# akka 工作端口,可选,默认 27777
powerjob.worker.akka-port=27777
# 接入应用名称,用于分组隔离,推荐填写 本 Java 项目名称
powerjob.worker.app-name=powerjob-agent-test
# 调度服务器地址,IP:Port 或 域名,多值逗号分隔
powerjob.worker.server-address=127.0.0.1:7700,127.0.0.1:7701
# 持久化方式,可选,默认 disk
powerjob.worker.store-strategy=disk
编写自己的处理器:随便找个地方新建类,继承你想要使用的处理器(各个处理器的介绍可见官方文档,文档非常详细),这里为了简单演示,选择使用单机处理器BasicProcessor,以下是代码示例。
@Slf4j
@Component
public class StandaloneProcessorDemo implements BasicProcessor {
@Override
public ProcessResult process(TaskContext context) throws Exception {
OmsLogger omsLogger = context.getOmsLogger();
omsLogger.info("StandaloneProcessorDemo start process,context is {}.", context);
System.out.println("jobParams is " + context.getJobParams());
return new ProcessResult(true, "process successfully~");
}
}
启动示例程序,即直接运行主类com.github.kfcfans.powerjob.samples.SampleApplication,观察控制台输出信息,判断是否启动成功。
STEP4: 任务的配置与运行
调度服务器与示例工程都启动完毕后,再次前往Web页面( http://127.0.0.1:7700/ ),进行任务的配置与运行。
在首页输入框输入配置的应用名称,成功操作后会正式进入前端管理界面。
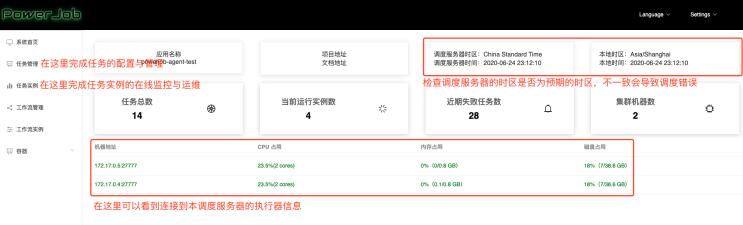
点击任务管理 -> 新建任务(右上角),开始创建任务。
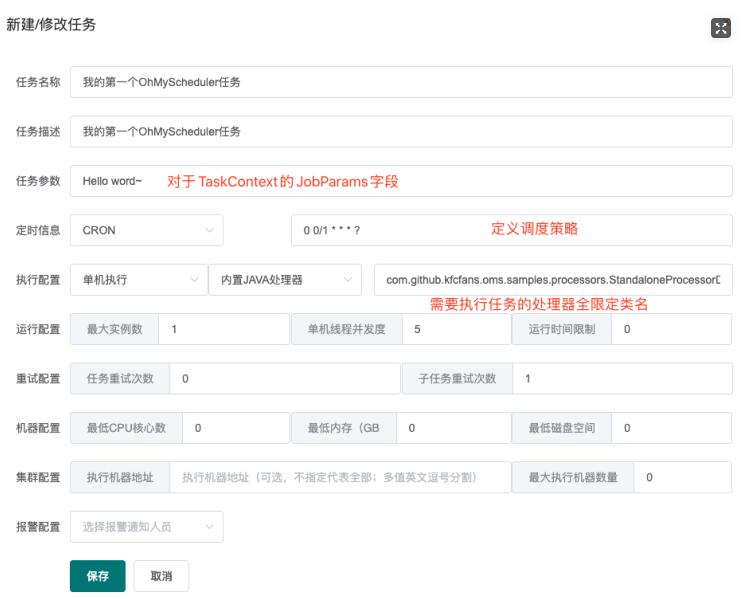
任务名称:名称
任务描述:描述
任务参数:任务处理时能够获取到的参数(即各个Processor的process方法入参TaskContext对象的jobParams属性)(进行一次处理器开发就能理解了)
定时信息:该任务的触发方式,由下拉框和输入框组成
API -> 不需要填写任何参数,表明该任务由OpenAPI触发
CRON -> 填写 CRON 表达式(在线生成网站)
固定频率 -> 填写整数,单位毫秒
固定延迟 -> 填写整数,单位毫秒
工作流 -> 不需要填写任何参数,表明该任务由工作流(workflow)触发
执行配置:由执行类型(单机、广播和MapReduce)、处理器类型和处理器参数组成,后两项相互关联。
内置Java处理器 -> 填写该处理器的全限定类名(eg, com.github.kfcfans.oms.processors.demo.MapReduceProcessorDemo)
Java容器 -> 填写容器ID#处理器全限定类名(eg,18#com.github.kfcfans.oms.container.DemoProcessor)
SHELL -> 填写需要处理的脚本(直接复制文件内容)或脚本下载链接(http://xxx)
PYTHON -> 填写完整的python脚本或下载链接(http://xxx)
运行配置
最大实例数:该任务同时执行的数量
单机线程并发数:该实例执行过程中每个Worker使用的线程数量(MapReduce任务生效,其余无论填什么,都只会使用必要的线程数...)
运行时间限制:限定任务的最大运行时间,超时则视为失败,单位毫秒,0代表不限制超时时间(不建议不限制超时时间)。
重试配置:
Instance重试次数:实例级别,失败了整个任务实例重试,会更换TaskTracker(本次任务实例的Master节点),代价较大,大型Map/MapReduce慎用。
Task重试次数:Task级别,每个子Task失败后单独重试,会更换ProcessorTracker(本次任务实际执行的Worker节点),代价较小,推荐使用。
注:请注意同时配置任务重试次数和子任务重试次数之后的重试放大,比如对于单机任务来说,假如任务重试次数和子任务重试次数都配置了1且都执行失败,实际执行次数会变成4次!推荐任务实例重试配置为0,子任务重试次数根据实际情况配置。
机器配置:用来标明允许执行任务的机器状态,避开那些摇摇欲坠的机器,0代表无任何限制。
最低CPU核心数:填写浮点数,CPU可用核心数小于该值的Worker将不会执行该任务。
最低内存(GB):填写浮点数,可用内存小于该值的Worker将不会执行该任务。
最低磁盘(GB):填写浮点数,可用磁盘空间小于该值的Worker将不会执行该任务。
集群配置
执行机器地址:指定集群中的某几台机器执行任务(debug的好帮手),多值英文逗号分割,如192.168.1.1:27777,192.168.1.2:27777
最大执行机器数量:限定调动执行的机器数量
报警配置:选择任务执行失败后报警通知的对象,需要事先录入。
完成任务创建后,即可在控制台看到刚才创建的任务,如果觉得等待调度太过于漫长,可以直接点击运行按钮,立即运行本任务。

前往任务示例边栏,查看任务的运行状态和在线日志
 猿编程电脑客户端(小学阶段编程课程学习) v5.42.0 官方版编程辅助
/ 86M
猿编程电脑客户端(小学阶段编程课程学习) v5.42.0 官方版编程辅助
/ 86M
 scratch3.0中文版(简易编程软件) v3.0 汉化免费版编程工具
/ 47M
scratch3.0中文版(简易编程软件) v3.0 汉化免费版编程工具
/ 47M
 易简玖大猫运行库合集正式版(游戏运行库) v3.0 免费版编程辅助
/ 971M
易简玖大猫运行库合集正式版(游戏运行库) v3.0 免费版编程辅助
/ 971M
 黑群晖DSM7.0iso镜像版(NAS操作系统)编程辅助
/ 216M
黑群晖DSM7.0iso镜像版(NAS操作系统)编程辅助
/ 216M
 scratch免激活版(附注册码) v2.0 授权版编程工具
/ 32M
scratch免激活版(附注册码) v2.0 授权版编程工具
/ 32M
 Primer 5(含注册机) 64位便携版编程工具
/ 1M
Primer 5(含注册机) 64位便携版编程工具
/ 1M
 cuda9.0官方版win10版编程工具
/ 1G
cuda9.0官方版win10版编程工具
/ 1G
 Pageoffice序列号永久免费版编程辅助
/ 10K
Pageoffice序列号永久免费版编程辅助
/ 10K
 pageoffice永久免费版免序列号版编程辅助
/ 30M
pageoffice永久免费版免序列号版编程辅助
/ 30M
 pc logo X64(Logo小海龟) v6.5 绿色版编程工具
/ 1.48M
猿编程电脑客户端(小学阶段编程课程学习) v5.42.0 官方版编程辅助
/ 86M
scratch3.0中文版(简易编程软件) v3.0 汉化免费版编程工具
/ 47M
易简玖大猫运行库合集正式版(游戏运行库) v3.0 免费版编程辅助
/ 971M
黑群晖DSM7.0iso镜像版(NAS操作系统)编程辅助
/ 216M
scratch免激活版(附注册码) v2.0 授权版编程工具
/ 32M
Primer 5(含注册机) 64位便携版编程工具
/ 1M
cuda9.0官方版win10版编程工具
/ 1G
Pageoffice序列号永久免费版编程辅助
/ 10K
pageoffice永久免费版免序列号版编程辅助
/ 30M
pc logo X64(Logo小海龟) v6.5 绿色版编程工具
/ 1.48M
pc logo X64(Logo小海龟) v6.5 绿色版编程工具
/ 1.48M
猿编程电脑客户端(小学阶段编程课程学习) v5.42.0 官方版编程辅助
/ 86M
scratch3.0中文版(简易编程软件) v3.0 汉化免费版编程工具
/ 47M
易简玖大猫运行库合集正式版(游戏运行库) v3.0 免费版编程辅助
/ 971M
黑群晖DSM7.0iso镜像版(NAS操作系统)编程辅助
/ 216M
scratch免激活版(附注册码) v2.0 授权版编程工具
/ 32M
Primer 5(含注册机) 64位便携版编程工具
/ 1M
cuda9.0官方版win10版编程工具
/ 1G
Pageoffice序列号永久免费版编程辅助
/ 10K
pageoffice永久免费版免序列号版编程辅助
/ 30M
pc logo X64(Logo小海龟) v6.5 绿色版编程工具
/ 1.48M





