

/中文/
/中文/
/中文/
/中文/
/中文/
/中文/
/中文/
/中文/
/中文/
/中文/
小编今天给大家找到了非常专业的网页数据采集工具,WebHarvy特别版这是一款网页数据获取软件,可以通过该软件,直接在网页上选择需要选择的资源,也可以将整个网页保存为html的格式,从而提取网页里面所有文本以及图标内容,WebHarvy破解版能够自动提取文字,图片,网址和电子邮件从网站,还可以多种格式保存从网页中提取数据,WebHarvy特别版特别的使用,赶快了解.
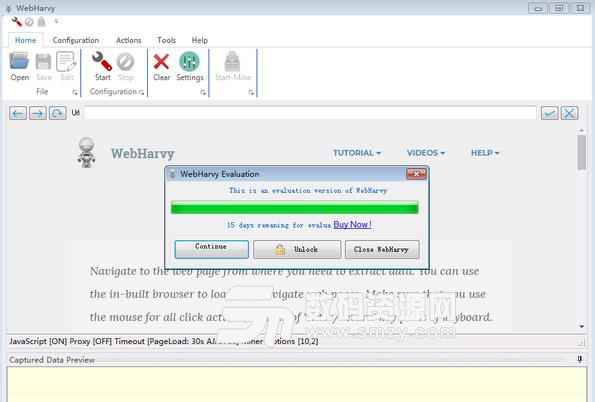
1、双击Setup.exe,点击next
2、勾选I accept,点击next
3、选择安装路径,点击next
4、点击install
5、安装完成点击finish退出,不要运行软件
6、将安装包中Fix文件夹下的WebHarvy.exe复制到软件安装目录中,点击替换目标中的文件
7、破解完成
支持在浏览器上复制链接搜索
支持配置对应资源项目搜索
可以使用项目名称以及资源名称查找
SysNucleus WebHarvy可以轻松提取数据
提供更高级的多词语搜索以及多页搜索
SysNucleus WebHarvy可以让您分析网页上的数据
可以显示从一个HTML地址上分析连接数据
可以延伸到下一个网页页面
可以指定搜索数据的范围以及内容
可以将扫描的图片下载保存
从多个页面提取
通常网页显示数据,如在多个页面中的产品目录。 WebHarvy可以自动抓取并从多个网页中提取数据。只是指出了“链接到下一页和WebHarvy网站刮板将自动刮从所有页面的数据。
基于关键字的提取
基于关键字的提取可让您捕捉从搜索结果页面输入关键字的列表数据。您创建的配置将被自动重复所有给定输入关键字,而挖掘的数据。可以指定任意数量的输入关键字
通过代{过}{滤}理服务器提取
提取匿名和防止提取网络软件被封锁的Web服务器,您必须通过代{过}{滤}理服务器访问目标网站的选项。可以使用一个单一的代{过}{滤}理服务器地址或代{过}{滤}理服务器的地址列表。
提取分类
WebHarvy网站刮板允许您从一个链接列表,从而导致一个网站内的相似页面抽取数据。这使您可以使用一个单一的配置刮网站内的类别或小节。
使用正则表达式提取
WebHarvy可以应用正则表达式(正则表达式)在文本或网页的HTML源代码,并提取去匹配的部分。这种强大的技术为您提供了更多的灵活性,同时拼抢的数据。
视觉点和点击界面
WebHarvy是一个可视化的网页提取工具。其实完全没有必要编写任何脚本或代码用来提取数据。使用WebHarvy的内置浏览器浏览网页。您可以选择用鼠标点击来提取数据。它是那么容易!
智能识别模式
自动识别网页中出现的数据模式。所以,如果你需要从一个网页刮项目(姓名,地址,电子邮件,价格等)的列表,你不需要做任何额外的配置。如果数据重复,WebHarvy会自动刮。
导出捕获的数据
可以保存从各种格式的网页中提取的数据。 WebHarvy网站刮板的当前版本允许你导出的刮数据作为XML,CSV,JSON或TSV文件。您还可以刮下数据导出到一个SQL数据库。
 uninstall tool密钥最新版网络辅助
/ 1K
uninstall tool密钥最新版网络辅助
/ 1K
 diskgenius离线激活码永久版网络辅助
/ 37M
diskgenius离线激活码永久版网络辅助
/ 37M
 守望先锋dva本子完整版(内含视频) 高清网盘版网络辅助
/ 1M
守望先锋dva本子完整版(内含视频) 高清网盘版网络辅助
/ 1M
 友邦微信群发软件(微信推广工具) v5.7 最新版网络辅助
/ 27.84M
友邦微信群发软件(微信推广工具) v5.7 最新版网络辅助
/ 27.84M
 吉吉影音资源BT种子(吉吉影音看片网站) 免费版网络辅助
/ 397K
吉吉影音资源BT种子(吉吉影音看片网站) 免费版网络辅助
/ 397K
 网页自动点击操作助手电脑版(自动刷网页点击数) v19.1.0 免费版网络辅助
/ 8M
网页自动点击操作助手电脑版(自动刷网页点击数) v19.1.0 免费版网络辅助
/ 8M
 CDR注册机(cdr永久激活代码) 免费版网络辅助
/ 323K
CDR注册机(cdr永久激活代码) 免费版网络辅助
/ 323K
 一片云验证码平台(验证码接收工具) v6.4 官方最新版网络辅助
/ 1004K
一片云验证码平台(验证码接收工具) v6.4 官方最新版网络辅助
/ 1004K
 360种子在线编辑器(360种子洗白工具) v1.0.1 绿色免费版网络辅助
/ 1M
360种子在线编辑器(360种子洗白工具) v1.0.1 绿色免费版网络辅助
/ 1M
 奥维互动地图vip账号分享工具(奥维地图vip账号大全) v2017 免费版网络辅助
/ 28M
吉吉影音资源BT种子(吉吉影音看片网站) 免费版网络辅助
/ 397K
uninstall tool密钥最新版网络辅助
/ 1K
diskgenius离线激活码永久版网络辅助
/ 37M
守望先锋dva本子完整版(内含视频) 高清网盘版网络辅助
/ 1M
友邦微信群发软件(微信推广工具) v5.7 最新版网络辅助
/ 27.84M
网页自动点击操作助手电脑版(自动刷网页点击数) v19.1.0 免费版网络辅助
/ 8M
CDR注册机(cdr永久激活代码) 免费版网络辅助
/ 323K
360种子在线编辑器(360种子洗白工具) v1.0.1 绿色免费版网络辅助
/ 1M
一片云验证码平台(验证码接收工具) v6.4 官方最新版网络辅助
/ 1004K
奥维互动地图vip账号分享工具(奥维地图vip账号大全) v2017 免费版网络辅助
/ 28M
奥维互动地图vip账号分享工具(奥维地图vip账号大全) v2017 免费版网络辅助
/ 28M
吉吉影音资源BT种子(吉吉影音看片网站) 免费版网络辅助
/ 397K
uninstall tool密钥最新版网络辅助
/ 1K
diskgenius离线激活码永久版网络辅助
/ 37M
守望先锋dva本子完整版(内含视频) 高清网盘版网络辅助
/ 1M
友邦微信群发软件(微信推广工具) v5.7 最新版网络辅助
/ 27.84M
网页自动点击操作助手电脑版(自动刷网页点击数) v19.1.0 免费版网络辅助
/ 8M
CDR注册机(cdr永久激活代码) 免费版网络辅助
/ 323K
360种子在线编辑器(360种子洗白工具) v1.0.1 绿色免费版网络辅助
/ 1M
一片云验证码平台(验证码接收工具) v6.4 官方最新版网络辅助
/ 1004K
奥维互动地图vip账号分享工具(奥维地图vip账号大全) v2017 免费版网络辅助
/ 28M





